
|
Authors: |
|
|
Scott MacLean |
Kevin Gray
|
Structural Equation Modelling (SEM) is a technique which effectively subsumes a whole range of standard multivariate analysis methods, including regression, factor analysis and analysis of variance.
Whilst being a sophisticated theoretical tool, and certainly not easy to implement, SEM actually underlies much of what practising market researchers do on a daily basis. That is, on the basis of things we can measure, we attempt to make predictions of things we cannot measure.
For market research, SEM provides an opportunity (in fact, a requirement) to hypothesise models of market behaviour, and to test or confirm these models statistically. In the paper, some examples are presented to show some of the benefits of this modelling approach.
Technically, SEM estimates the unknown coefficients in a set of linear structural equations. Variables in the equation system are usually directly observed variables, and unmeasured latent variables that are not observed but relate to observed variables.
SEM assumes there is a causal structure among a set of latent variables, and that the observed variables are indicators of the latent variables. The latent variables may appear as linear combinations of observed variables, or they may be intervening variables in a causal chain.
One of the findings deriving from the examples presented in the paper is that conclusions drawn from techniques such as Exploratory Factor Analysis and regression (eg as used in many customer satisfaction approaches) may be unsustainable in terms of their statistical integrity.
To paraphrase Byrne (1994), Structural Equation Modelling (SEM) is a statistical methodology that takes an hypothesis-testing (ie confirmatory) approach to the multivariate analysis.
By contrast, multivariate procedures commonly used in market research are essentially descriptive or exploratory in nature (eg principal components analysis, cluster analysis), so that hypothesis testing is difficult, if not impossible.
SEM generally involves the specification of an underpinning linear regression-type model (incorporating the structural relationships or equations between unobserved or latent variables) together with a number of observed or measured indicator variables. By examining the co-variation between the observed variables, it is possible to:
For market research, SEM provides an opportunity to hypothesise models of market behaviour, and to test these models statistically. In this paper, examples and case studies will be presented which show, in part, that conclusions drawn from what are now fairly standard applications of techniques such as Exploratory Factor Analysis and regression (eg as used in many customer satisfaction approaches) may be unsustainable in terms of their statistical integrity.
A Structural Equation Model in its most general form involves the specification of a number of components which, when pictured in full detail, can be more than daunting to the tyro modeller. Anyone who has perused the LISREL® (1989) documentation will surely agree with this! [See also Long (1983) for a simpler treatment of LISREL®]
It is therefore instructive to examine the various elements of SEM, one by one. First, however, a small parable may be of assistance.
Let us take a brief sojourn to Omote-sando, one of Tokyo's chic fashion districts. Here in Omote-sando we observe a young woman - let us call her Yumi - emerging from one of the trendy and very expensive boutiques which are abound in this area. Elegantly and expensively dressed and coiffured, it is apparent to us that Yumi pays a great deal of attention to her appearance. In market research jargon, we might also say she appears very "fashion-conscious."
Though we often use terms such as "fashion-conscious" casually, it is important to recognise that fashion-consciousness is in reality a theoretical construct; we cannot actually see it but can only infer its presence from what we can observe. In other words, it is a latent or unobserved variable. In our example, we can observe Yumi's dress and manner and the Omote-sando boutique at which she's been shopping and make the inference that she is fashion-conscious.
One may object and conclude instead that Yumi is simply materialistic. Materialism is another example of a latent or unobserved variable. Or, one may determine she is both fashion-conscious and materialistic. In this case we would, in effect, be saying that these two latent variables are correlated.
Naturally, in Market Research we would not normally venture into Omote-sando, observe young women like Yumi and speculate about latent variables. We often do, however, administer questionnaires to consumers which probe for concepts such as "fashion-consciousness", "materialism", etc. By asking them to make self-assessments on items such as "I usually have one or more outfits that are of the very latest style," we are attempting to measure the extent of their fashion-consciousness, etc., though we recognise that we cannot do so perfectly. (That is, we can measure but only with error.)
The statement "I usually have one or more outfits that are of the very latest style" is an example of a measurable variable and, similarly, "fashion-consciousness" is an example of an unmeasurable, latent variable. To relate this to our earlier discussion, by asking Yumi to make self-assessments such as this, we are attempting to indirectly measure a latent variable which is, in fact, a theoretical construct which cannot be measured directly.
Thus, unobserved or unmeasured, latent variables are those which represent abstract concepts or theoretical constructs which cannot be directly measured. Such variables are often referred to as 'factors' or 'common factors'. That is, they are presumed to underlie what can be observed, in the sense that the latent variables directly influence the outcome or values taken by the observed variables.
In pictorial form, latent variables can be represented as ellipses, as shown in Figure 1.
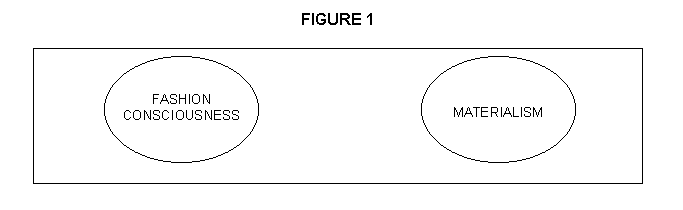
Latent variables can be correlated with each other, as represented by the double-headed arrow in Figure 2.
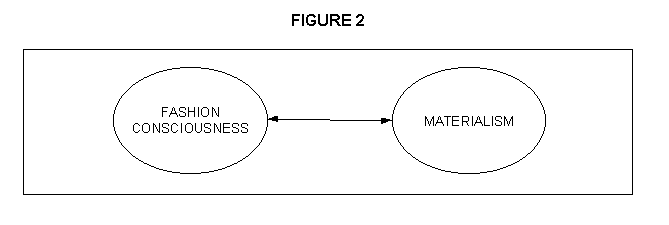
Latent variables can also influence other latent variables directly, via a regression-type relationship, as represented by the single-headed arrows below:
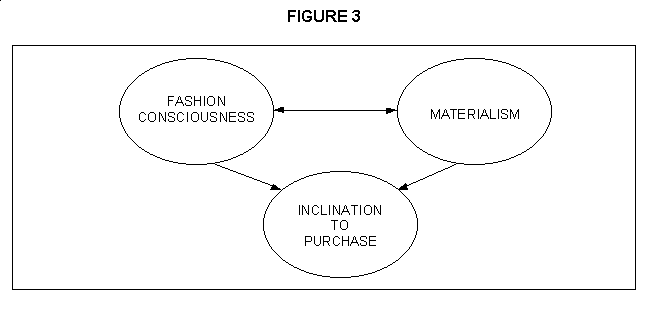
Because latent variables are, by definition, unobservable, their measurement must be obtained indirectly.
This is done by linking one or more observed variables to each unobserved variable. In fact, whilst this may sound an overly-fussy process, as shown in the case of our Japanese shopper Yumi, it is effectively what most of us do on a day-to-day basis as we prepare questionnaires. The difference, however, lies in how we analyse the information we collect.
With SEM, the linking of observed (or indicator) variables with latent (or unobserved) variables is the first step in a formal statistically valid procedure. In contrast, with our day-to-day work the linking procedure is oftentimes implicit - in other words, if we feel that a particular measured variable makes a good indicator of some underlying construct, then we simply use it !
In pictorial form, observed or indicator variables can be represented as rectangles, as shown in Figure 4.
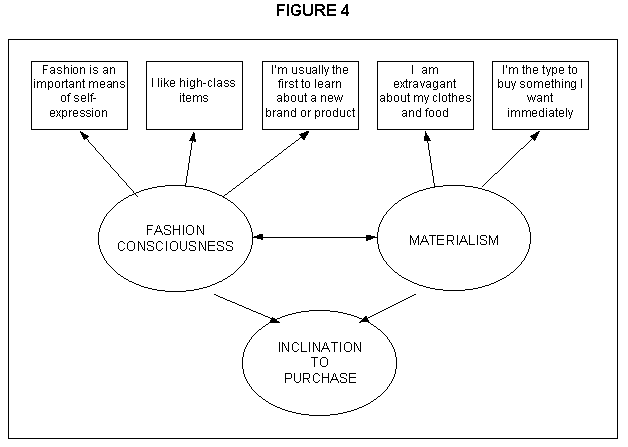
In this diagram, the single-headed arrows connecting the latent and observed variables indicate that the latent variables directly influence the outcome or values taken by the observed variables, again through a regression-type relationship.
We can go still further, in terms of identifying observed variables for the completely endogenous latent variable labelled as "Inclination to purchase", as illustrated in Figure 5.
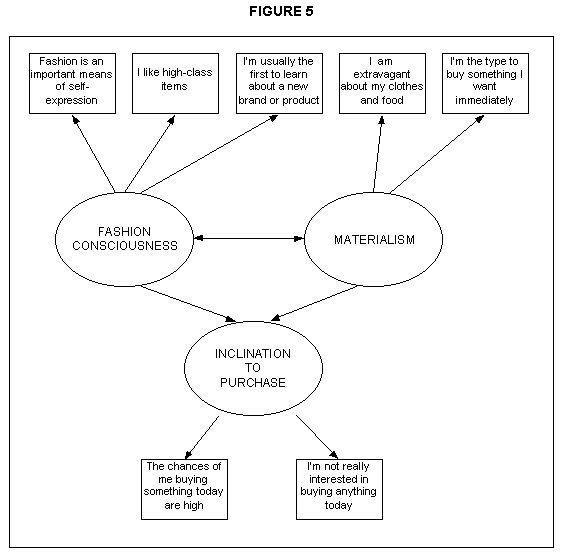
Apart from the latent and observed variables, there are residual and error terms associated with each of these which also form a key part of the overall model. For simplicity, however we omit these from the discussion, and refer the interested reader to the bibliography.
Suffice it to say that a fully specified Structural Equation Model is potentially a complex interplay between a large number of observed and unobserved variables, and residual and error terms.
In order to illustrate the concepts of observed/measured and unmeasured/latent variables we have already introduced you to a fictitious young woman whom we called Yumi. Fashion Consciousness and Materialism were used as examples of unmeasured/latent variables, and it was hypothesised that these two latent variables might be inter-correlated. We would now like to proceed beyond allegory and share some results of an actual study conducted among consumers who, in many aspects, are very much like Yumi.
Recently, SRG Japan conducted a U&A study on overseas travel among young Japanese single women -- OLs in the local vernacular. The term OL is an abbreviation of "Office Lady" and is widely used in Japan to refer to single women working in non-management and non-technical occupations, most often clerical work. Although their earned incomes are typically not high, OLs are one of the most important consumer groups in Japan because they often live with their parents rent-free and tend to have significant disposable incomes -- incomes which they frequently spend quite freely. Another distinction OLs have which is important to the travel industry is that they often have more freedom to travel during any time of the year than other consumer groups.
A key objective of this research was to explore personality factors underlying OLs' preferences for overseas destinations and travel arrangements. Consequently, during the interviews, respondents rated themselves on a battery of psychographic items which had been developed through preliminary qualitative research.
The qualitative phase of the research had suggested five principal psychographic factors of relevance to overseas travel experience and tastes. These were:
Each of these latent constructs was measured by three to four measured variables (items). These are shown in Figure 6.
FIGURE 6
MEASURED VARIABLES FOR EXAMPLE I
- JAPANESE SINGLE WOMEN -
Fashion Consciousness
V13 Fashion is an important means of self-expression
V20 I like high-class items
V21 I'm usually the first among my friends to learn about a new brand or product
Materialism (or "Extravagance")
V31 I am extravagant about my clothes and food
V34 I'm the type to buy something I want immediately even if I have to borrow money
V37 I'm the type that doesn't hesitate to buy necessary things even if they are somewhat expensive
Assertiveness
V14 I make friends quickly even with people I've just met
V17 I challenge anything without fear of failure
V33 I socialise with many different types of people
V39 I am the type to clearly state my opinions to others
Conservatism (or "Deliberateness")
V3 I tend to achieve my goals one step at a time
V6 I am the type to deliberate things
V7 I gather various information and study well when deciding to buy a specific item
Hedonism
V1 I want to enjoy the present rather than think about the future
V9 I like to go out to night-time entertainment spots
V12 I want to lead a life with lots of ups and downs
Based on the qualitative research and Exploratory Factor Analysis (EFA) of the quantitative results, a number of Structural Equation Models were developed and tested, each of which hypothesised different inter-relationships among the five latent constructs listed above. The path diagram representing the model we consider most meaningful in light of the overall findings of the research is shown in Figure 6.
To build upon our earlier discussion, in the path diagram, latent constructs (unmeasured variables) are shown in ellipses and questionnaire items used to measure these latent constructs ie., measured variables, are shown in rectangles. Arrows pointing from the circles to the rectangles are equivalent to factor loadings in factor analysis. With two exceptions, all loadings were above 0.50. Arrows between the unobserved variables represent correlations among these factors (since correlations are two-way associations, all arrows between the unobserved variables are two-headed).
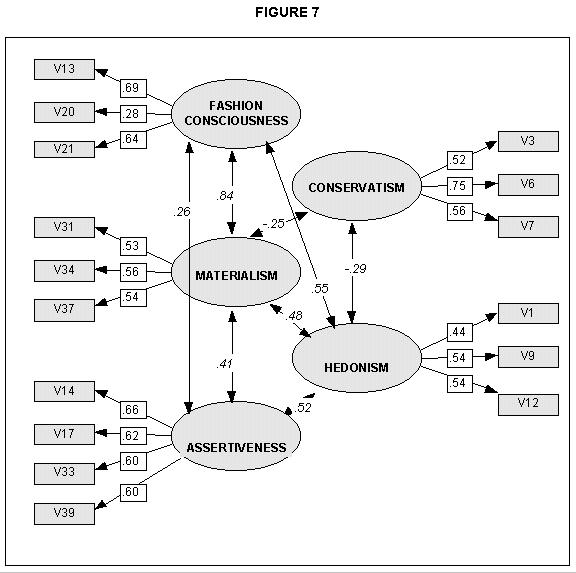
To many readers of a Western background, the overall results may seem surprisingly intuitive. Fashion Consciousness and Materialism were, indeed, found to be highly associated and in a positive direction. Indeed, this correlation (0.84) is so strong as to suggest these two factors themselves may really be functions of a second-order factor, though the confirmation of this would need further research Materialism and Assertiveness are also found to be positively related but more weakly. The correlation between Assertiveness and Fashion Consciousness is weakly positive (0.26) but, nonetheless, statistically significant.
Looking to the right side of the diagram, we see that Conservatism and Hedonism are negatively associated. This relationship also is weak but significant. We also note that Fashion Consciousness, Materialism and Assertiveness are all moderately positively associated with Hedonism. And, as had been anticipated, Materialism and Conservatism are negatively related in this research, though this relationship is not strong.
In an earlier preliminary model, Fashion Consciousness and Assertiveness were not found to be associated with Conservatism, and these paths were deleted prior to testing the present model.
To recapitulate, fashion conscious OLs are also inclined to be on the spendthrift side and to have a hedonistic streak, though they are not necessarily exceptionally assertive or extroverted. Given these patterns, when vacationing abroad one might expect they would tend to look for an abundance of places to shop, especially for high-priced/fashion goods. Choice restaurants and perhaps nightspots would probably also be considerations for many of them when choosing a travel destination and/or travel package.
More conservative or methodical types, on the other hand, would be expected to be less extravagant, fashion conscious and assertive and also less hedonistic. Other results for this survey suggested these young women might, instead, be more inclined to enjoy the local flavour of their destination or simply relax.
So far, so good. We have a nice looking picture which (for our example) makes a certain amount of sense in terms of describing the key relationships in a model of market behaviour.
In fact, what we have is more than that. Firstly, the diagram indicates that there is an hypothesised relationship between a number of latent variables which forms the underpinning casual structure of behaviour in this market. This is the so-called structural model.
Secondly, the diagram indicates that there is a number of variables which we can directly observe, the statistical relationships between which we may be able to use to calibrate the underlying structural model. This set of statistical relationships is the so-called measurement model. [Recall that the latent variables are linked to each other via regression-type relationships, so that calibration in this context simply means estimating values for the relevant regression coefficients.]
The central thesis of SEM is then twofold:
Let's have a look at one more illustrative case study to try to make things clearer, before summarising our conclusions.
In 1996, AGB McNair (now A C Nielsen) undertook an Employee Opinion Survey, the objective of which was to obtain benchmark information regarding the current attitudes of Australian employees to their work environment.
A drop-off and mail-back methodology was used. Questionnaires were placed with employed respondents aged 16 years and over by AGB McNair Face to Face Omnibus interviewers.
A total of 740 completed questionnaires were returned.
Information was collected on the following seven categories:
Respondents were asked to rate whether they agreed or disagreed with a number of statements under each of the above categories using the following scale:
The categories themselves, and the various statements which underpin them, were selected so as to be broadly consistent with the criteria laid down by the Australian Quality Council, in relation to the Australian Quality Awards Assessment Framework. Details may be found in AQC (1996).
In the AGB McNair (1996) report, analysis of the information was carried out for a number of key demographics, including:
In the present context, however, it is instructive to take a leaf out of the SEM book and treat the seven categories as subsuming a number of latent, unobserved variables, and the various underpinning statements as comprising the measured variables to be used as indicators of the latent constructs.
Whilst the Employee Opinion Survey was not designed with this type of analysis in mind (indeed, nor was the earlier Yumi example), it is certainly possible to hypothesise the nature and direction of the relationships which exist amongst the latent variables, and thereby test the statistical and practical significance of the associated structural model.
These types of data are normally analysed by means of an Exploratory Factor Analysis (EFA), usually implemented in the form of Principal Components Analysis (see, for example, Johnson and Wichern (1992)). Regression of the resultant factor scores (see Pedhazur (1982)) against some overall criterion measure (eg Overall Satisfaction) gives rise to standardised regression coefficients, which can be normalised (ie re-scaled so as to add to 100) and, it is claimed, thereby give an indication of the relative importances of the different factors.
As an illustration, consider the category Quality and Safety. In the Employee Opinion Survey, nine statements were used as the measured variables for this construct, as shown in Figure 8.
FIGURE 8
MEASURED VARIABLES FOR EXAMPLE II
- AUSTRALIAN EMPLOYEE SATISFACTION -
A casual inspection of the statements themselves suggests that there may be two factors (latent variables) which underlie them:
Sure enough, if we carry out a Principal Components Analysis, two factors emerge which we may call 'safety' and 'efficiency/quality' with (rotated) loadings as shown in Figure 9 (total variance explained is 59%).
Regression of the individual factor scores against Overall Satisfaction (R-square = .30; Std error = .87), and inspection of the standardised regression coefficients, yields the following result concerning relative importances:
Safety 52%
Efficiency/Quality 48%.
On the face of it, this is a clear and simple conclusion. Based on our data, we infer that in terms of the impact on Overall Employee Satisfaction, the factors of Efficiency/Quality and Safety are of almost equal importance. And this is the type of result that is presented to management and clients every day in the market research world.
FIGURE 9
|
STATEMENT |
FACTOR 1: SAFETY |
FACTOR 2: EFFICIENCY/ QUALITY |
|
Managers/supervisors talk with people about safety issues |
.744
|
|
|
Unsafe acts and conditions are never ignored and are reported by all personnel
|
.809
|
|
|
Safety is never overridden by work/production issues
|
.826
|
|
|
There is a positive link between quality and safety
|
.753
|
|
|
A clean and tidy workplace is encouraged
|
.556
|
.408
|
|
Our team is continually looking for more ways to reduce waste (time and resources)
|
|
.663
|
|
When an employee here is off sick or injured, he/she tries to get back to work as soon as possible |
|
.842 |
|
If I am injured at work, I feel I would be well looked after |
|
.575
|
|
Quality is never sacrifice by work pressures
|
.446
|
.565
|
Note: for clarity only loadings greter than 0.4 are shown
Consider, however, that:
The alternative is to do all of these things on the one pass, using the techniques of Structural Equation Modelling.
Using the SEM approach, a factor structure would normally be hypothesised based on a variety of considerations (eg the results of qualitative research), the necessary model defined, and its adequacy tested statistically.
Instead, as a short cut (although not generally advisable - see Bentler (1995)), in many cases the results of an Exploratory Factor Analysis may themselves be used to define a factor structure. Thus, with our present example we might postulate that the factor structure which underlies the Safety/Quality questions is as shown in Figure 10.
FIGURE 10
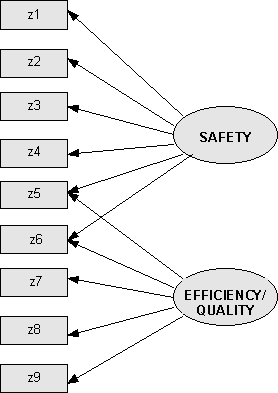
Here, the 'z' variables correspond to the statements listed earlier, administered in the questionnaire via an 'agree/disagree' scale. The arrows show that the 'z' variables are indicators of the two underlying latent constructs, or factors, namely Safety and Efficiency/Quality. In other words, the diagram simply represents the factor analysis solution shown in the table earlier (Figure 9).
It should also be noted that two of the measured variables are assumed to be associated with more than one factor.
When the necessary calculations have been completed, we obtain the results shown in Figure 11 (standardised coefficients shown):
FIGURE 11
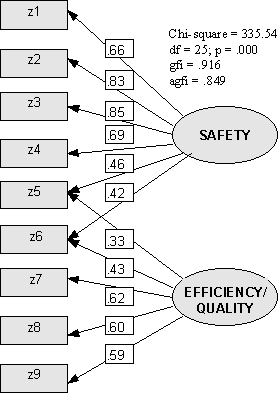
Several items of information are contained in the above picture, and the implications are immediately discernible. Firstly, the standardised regression coefficients from the Structural Equation Model are roughly the same as the factor coefficients arising from the Exploratory Factor Analysis (as we hope they would be). In Figure 12 the two sets of results are compared.
The reason they are different, of course, is that the EFA solution assumes that every indicator variable is statistically related (correlated) with every factor. In contrast, the SEM solution assumes that the only indicator variables correlated with the factors are those shown linked by an arrow (in fact a much more flexible arrangement for model specification).
Secondly, and more importantly, from the EFA we have a lot more, specifically in relation to the 'goodness' of the solution.
FIGURE 12
|
STATEMENT |
FACTOR 1: SAFETY |
FACTOR 2: EFFICIENCY/ QUALITY |
||
|
Managers/supervisors talk with people about safety issues
|
EFA |
SEM |
EFA |
SEM |
|
.74
|
.66
|
|
|
|
|
Unsafe acts and conditions are never ignored and are reported by all personnel
|
.81
|
.83
|
|
|
|
Safety is never overridden by work/production issues
|
.83
|
.85
|
|
|
|
There is a positive link between quality and safety
|
.75
|
.69
|
|
|
|
A clean and tidy workplace is encouraged
|
.56
|
.46
|
.41
|
.43
|
|
Our team is continually looking for more ways to reduce waste (time and resources)
|
|
|
.66
|
.62
|
|
When an employee here is off sick or injured, he/she tries to get back to work as soon as possible
|
|
|
.84
|
.60
|
|
If I am injured at work, I feel I would be well looked after |
|
|
.58 |
.59 |
|
Quality is never sacrifice by work pressures |
.45 |
.42 |
.57 |
.33
|
One measure of the goodness-of-fit of the EFA solution is given by the chi-square value of 335.54, which is highly significant (p = .000). Note, however, that this does not mean our model is 'good'. In fact it is the opposite, from the point of view of statistical significance. In fact, one may say that what we are actually testing is "badness-of-fit".
The reason why a low p-value implies a 'bad' model is that the null hypothesis for this test is that the model is a good model. So a low p-value (that is, one close to zero) means that we reject the null hypothesis, with a low probability of being wrong in reaching that conclusion. Conversely, a high p-value (ie, a value larger than zero) would mean that if we did reject the null hypothesis (ie. conclude that the model is bad) then there would be a high probability that we would be wrong in doing so.
However, whilst the chi-square value is too large (ie. the p-value is too small) to be able to accept our model on strict statistical grounds, the other goodness-of-fit measures quoted are not too bad. There is a huge literature on testing the 'goodness-of-fit' of SEM solutions. The principal consensus seems to be that there is no consensus on which is the best approach. Bollen and Long (1993) provide probably the best discussion of the many issues involved. The so-called Goodness-of-Fit Index (GFI) is .916, and the Adjusted Goodness-of-Fit Index (AGFI) is .849. The best you can get is unity with these two measures, so on the basis of the results obtained, we would probably say that the model is 'good enough'.
We can improve things further by allowing for a degree of co-variation between the factors, with results as shown in Figure 13.
FIGURE 13
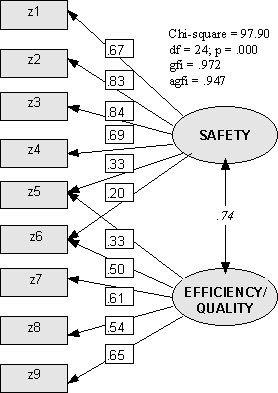
This second model allows for a degree of correlation (in fact, an r-value of .74) between the two factors. Further, by including this extra parameter, we have in fact improved the fit, as measured by the GFI and the AGFI. The chi-square value is still too large (ie. we still have p = .000) although it has certainly improved. On this basis, we would say that our second model is better. It is actually possible to statistically test which of several competing SEMs is the best, but we do not pursue this in this paper. The interested reader is invited to consult some of the references.
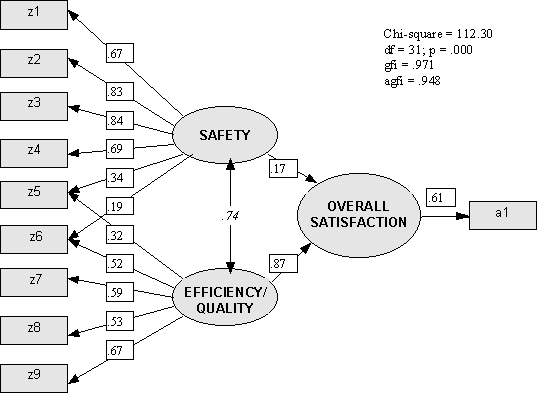
Next we look at the impact of Efficiency/Quality and Safety on Overall Employee Satisfaction. Using SEM we can make a simple addition to the model, as shown in Figure 14.
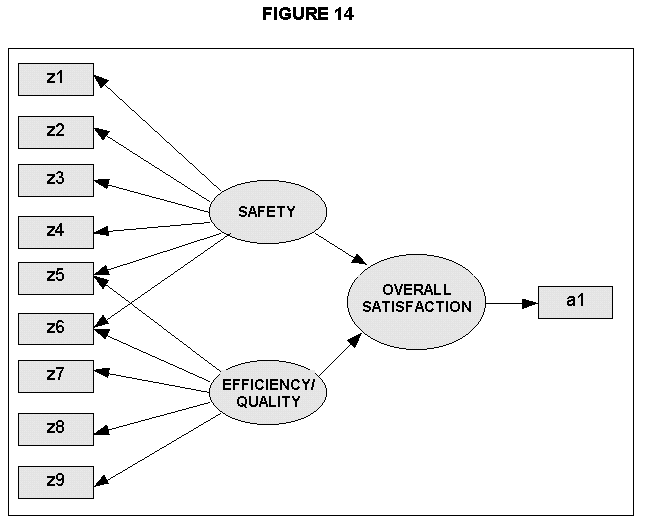
In other words, we have the same model as before, but now we are specifically providing for an underlying structural model which relates the latent constructs Safety and Efficiency/Quality to the latent construct Overall Satisfaction via a regression-type relationship. The latent variable Overall Satisfaction is measured by just one indicator variable, labelled as 'a1' in the diagram and represented in the original questionnaire by the question "How satisfied are you overall with working at your organisation?"
The results are shown in Figure 15.
We have a direct parallel to the results obtained from the EFA approach described earlier. But in contrast to the EFA approach, where Safety and Efficiency/Quality were seen to have almost equal impact on Overall Satisfaction, the SEM results show that Safety is of considerably lesser significance in its impact on Overall Satisfaction than the EFA approach would suggest. In addition, we have simultaneously provided an estimate of the correlation which undoubtedly exists between the two factors, to show the close relationship between them.
FIGURE 15
In fact, SEM allows models to be developed which are of almost unbelievable complexity, and which allow the direct calibration of sophisticated interplays of latent and measured variables.
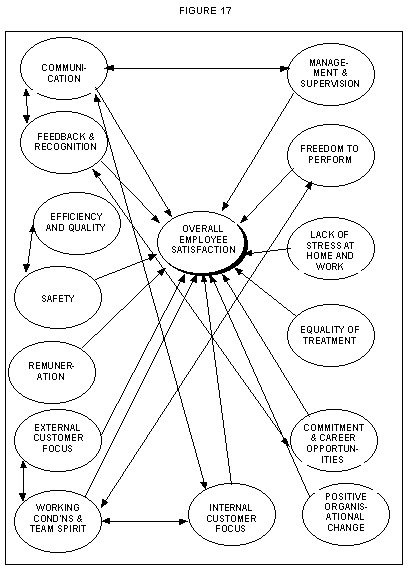
As an indication of what we mean, we have used the employee data to calibrate quite a complicated model, which takes into account the likelihood that several of the hypothesised underlying latent variables will in fact be correlated with one-another. The results from one such model are shown in Figure 16, with the model shown in diagrammatic form in Figure 17.
Whilst this model is presented here primarily for illustrative purposes, for those who may be interested in some conclusions, we make a few comments.
Firstly, whilst the GFI and AGFI indices are somewhat too low for comfort, the chi-square results in relation to the degrees of freedom are not too bad. On this basis, we would probably accept the model on a preliminary basis, with an intention of refining it further.
Secondly, the correlations (indicated in Figure 17 by the double-headed arrows) are almost all greater than zero and statistically significant.
Thirdly, the relativities between the standardised regression coefficients (indicated in Figure 17 by the single-headed arrows) are interesting - in terms of the impact on Overall Employee Satisfaction they are as shown in Figure 16 for the total sample, and also for just two of the 13 employee categories represented in the survey. It can be seen that:
FIGURE 16
|
Latent Construct |
Standardised Regression Coefficients |
||
|
|
TOTAL (incl. 13 employment categories) |
RETAIL (category 7) |
HEALTH AND COMMUNITY SERVICES (category 11) |
|
Commitment and Career Opportunities |
.835 |
.294 |
.487 |
|
Working Conditions and Team Spirit |
.403 |
* |
.960 |
|
Management and Supervision |
.344 |
* |
* |
|
Lack of Stress at Home and Work |
.308 |
.522 |
.347 |
|
Equality of Treatment |
.304 |
* |
* |
|
Remuneration |
.194 |
.246 |
.322 |
|
Safety |
* |
* |
* |
|
Positive Organisational Change |
.158 |
.251 |
* |
|
Internal Customer Focus |
* |
* |
* |
|
Communication |
* |
* |
* |
|
Efficiency/Quality |
* |
-.330 |
* |
|
Freedom to Perform |
* |
* |
* |
|
External Customer Focus |
* |
* |
-.512 |
|
Feedback and Recognition |
* |
* |
* |
|
Chi-square; df |
8987.3; 1805 |
3857.4; 1805 |
4216.3; 1805 |
|
gfi |
.629 |
.417 |
.520 |
|
agfi |
.599 |
.369 |
.481 |
Note: Non-significant coefficients are shown as a *.
In this brief paper, we hope we have been able to demonstrate the following:
plus many others.
We would therefore urge the reader to consult some of the references given, and develop an appreciation of a technique which we are convinced is deserving of, and which will receive, more widespread application in market research in the near future.
AGB McNair (1996) People ... An Organisation's Most Important Resource ... But Are They Empowered To Meet The Challenges Facing Australian Organisations? Syndicated Research Report prepared by Sarah Wrigley.
AMOS (1996) AMOS Users' Guide Version 3.6, Smallwaters Corporation.
AQC (1996) Australian Quality Awards Assessment Criteria Australian Quality Council.
Bentler, Peter M. (1995) EQS Structural Equations Program Manual, Encino, CA: Multivariate Software Inc.
Bentler, Peter M. and Wu, Eric J. C. (1995) EQS for Windows User's Guide, Encino, CA: Multivariate Software Inc.
Bollen, Kenneth A. (1989) Structural Equations with Latent Variables, John Wiley and Sons
Bollen, Kenneth A. and Long, J. Scott (1993) Testing Structural Equation Models, Sage Publications
Byrne, Barbara M (1994) Structural Equation Modelling with EQS and EQS/Windows - Basic Concepts, Applications and Programming SAGE Publications.
Johnson, Richard A. and Wichern, Dean W. (1992) Applied Multivariate Statistical Analysis 3rd edn. pp. 340-347; 356-458 Prentice Hall.
LISREL® (1989) LISREL® 7 - A Guide to the Program and its Applications, 2nd edn, JÖRESKOG and SÖRBOM/SPSS Inc.
Long, J. Scott (1983) Covariance Structure Models - An Introduction to LISREL® SAGE Publications.
Pedhazur, Elazar J (1982) Multiple Regression in Behavioural Research - Explanation and Prediction 2nd ed. pp. 575-681 Holt, Rinehart and Winston.
SEMNET FAQ (1997) http://www.gsu.edu/~mkteer/semfaq.html